1University of Chinese Academy of Sciences 2Meituan
†Corresponding author
Text-to-image (T2I) generation has achieved remarkable progress in instruction following and aesthetics. However, a persistent challenge is the prevalence of physical artifacts, such as anatomical and structural flaws, which severely degrade perceptual quality and limit application. Given the diversity and complexity of these artifacts, a systematic and fine-grained evaluation framework is required, which is lacking in current benchmarks. To fill this gap, we introduce MagicMirror, a comprehensive framework for artifacts assessment. We first establish a detailed taxonomy of generated image artifacts. Guided by this taxonomy, we manually annotate MagicData340K, the first human-annotated large-scale dataset of 340K generated images with fine-grained artifact labels. Building on this dataset, we train MagicAssessor, a Vision-Language Model (VLM) that provides detailed assessments and corresponding labels. To overcome challenges like class imbalance and reward hacking, we design a novel data sampling strategy and a multi-level reward system for Group Relative Policy Optimization (GRPO). Finally, we leverage MagicAssessor to construct MagicBench, an automated benchmark for evaluating the image artifacts of current T2I models. Our evaluation with MagicBench reveals that despite their widespread adoption, even top-tier models like GPT-image-1 are consistently plagued by significant artifacts, highlighting artifact reduction as a critical frontier for future T2I development.

Given an image generated by an AIGC model and its corresponding prompt, our model can detect artifacts that appear in the image. In this example, an artifact in the car's rearview mirror is accurately identified.
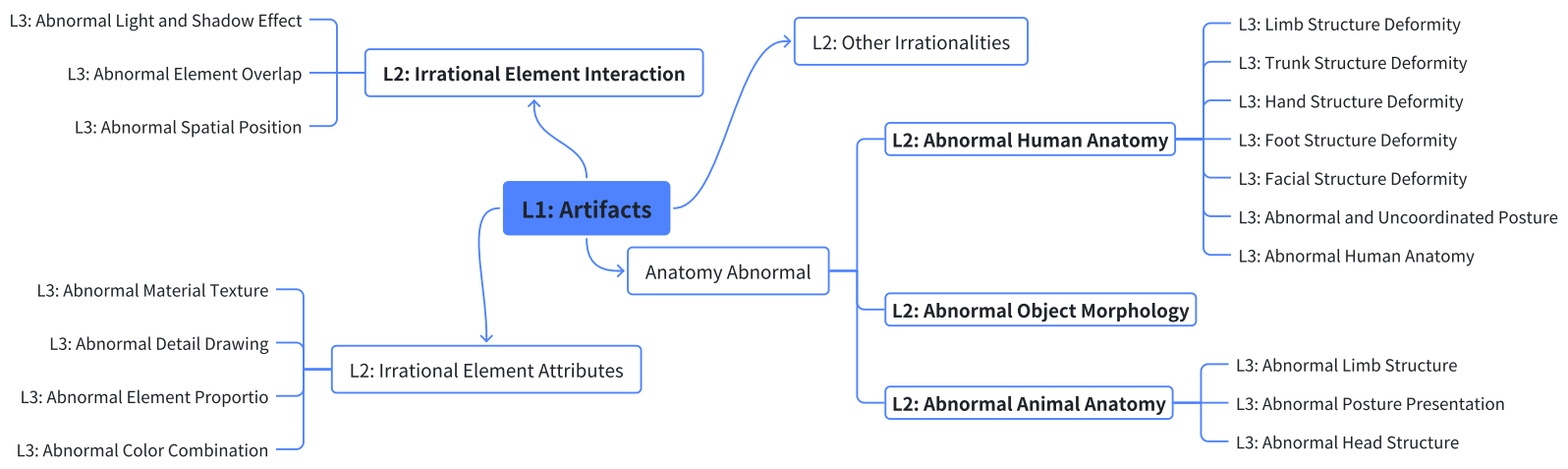
We define Normal/Artifact as Level 1 (L1). At the highest level, we distinguish between artifacts concerning the subject itself and those involving interactions between subjects. Subject-level issues are further divided into Anatomy (including human, animal, and object structure) and Attributes (including color and proportion). These main categories constitute our Level 2 (L2) labels. For critical areas, we define more specific Level 3 (L3) labels, such as Hand Structure Deformity.

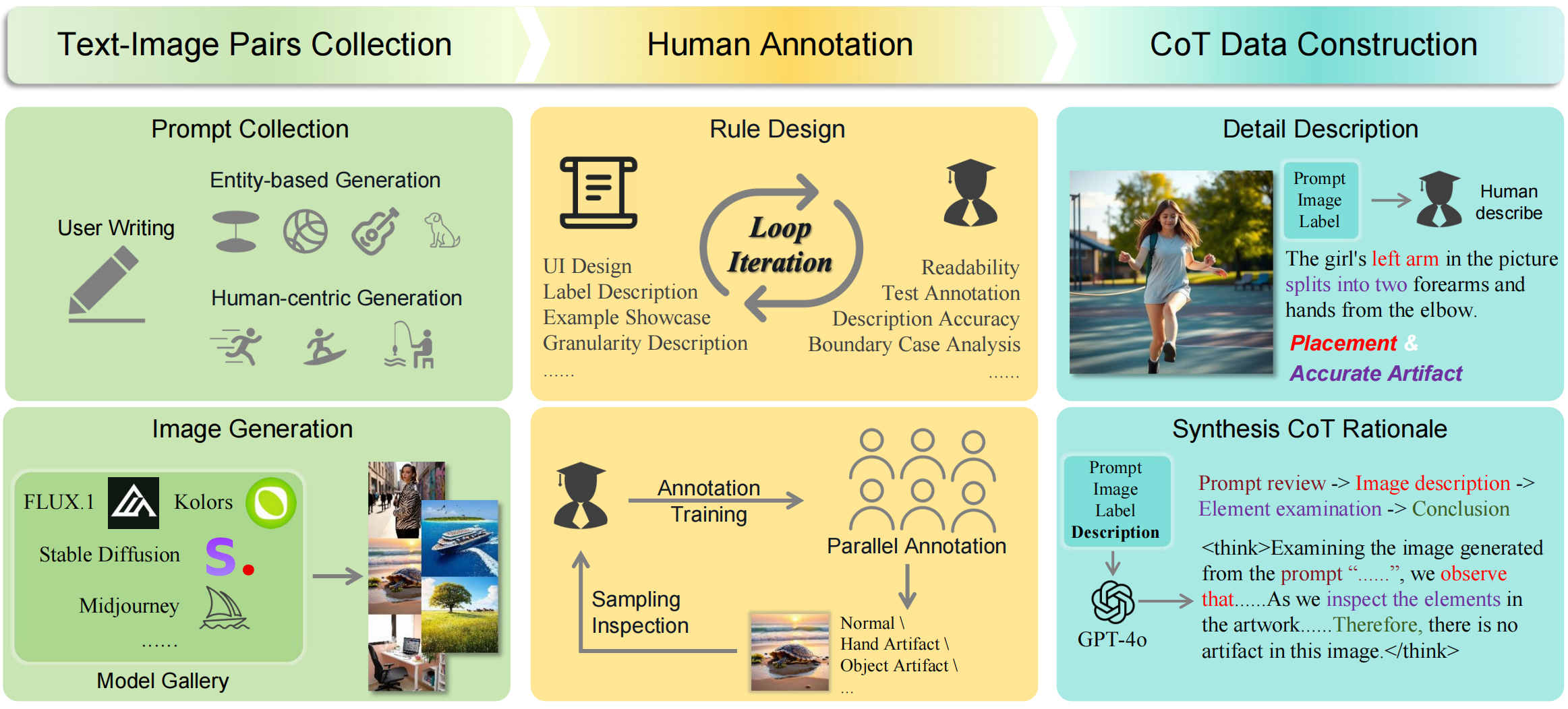
The process begins with curating prompts from diverse sources and generating corresponding images with a suite of T2I models. A comprehensive annotation taxonomy for artifacts is then developed through iterative tests and applied to the resulting text-image pairs. Finally, a representative subset is selected for fine-grained annotation, where detailed descriptions for each label are written by humans and used to synthesize Chain-of-Thought (CoT) rationales with GPT-4o.
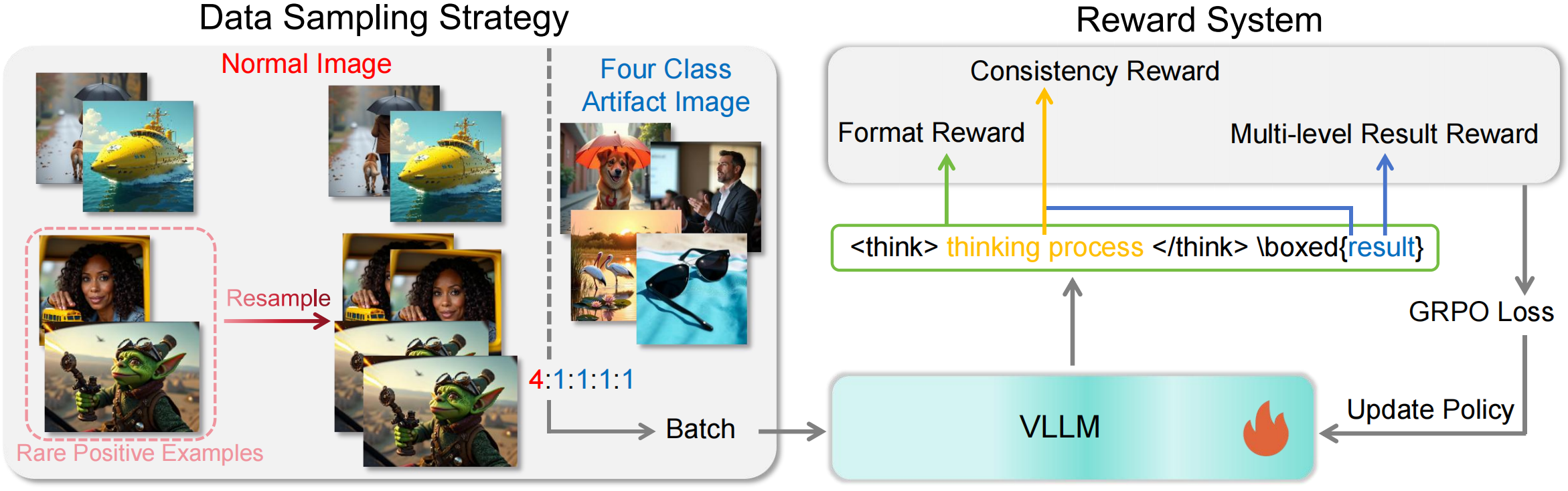
To enhance its performance, we employ GRPO, which we uniquely adapt to our task through two key innovations: a targeted data sampling strategy and a multi-level reward system. First, to address the issue of data imbalance, our data sampling strategy oversamples challenging positive cases, such as anatomically correct hands. Then, we propose a multi-level reward system, which guides the model from coarse to fine-grained detection and introduce a novel consistency reward to align the model's reasoning with its final output to prevent reward hacking.
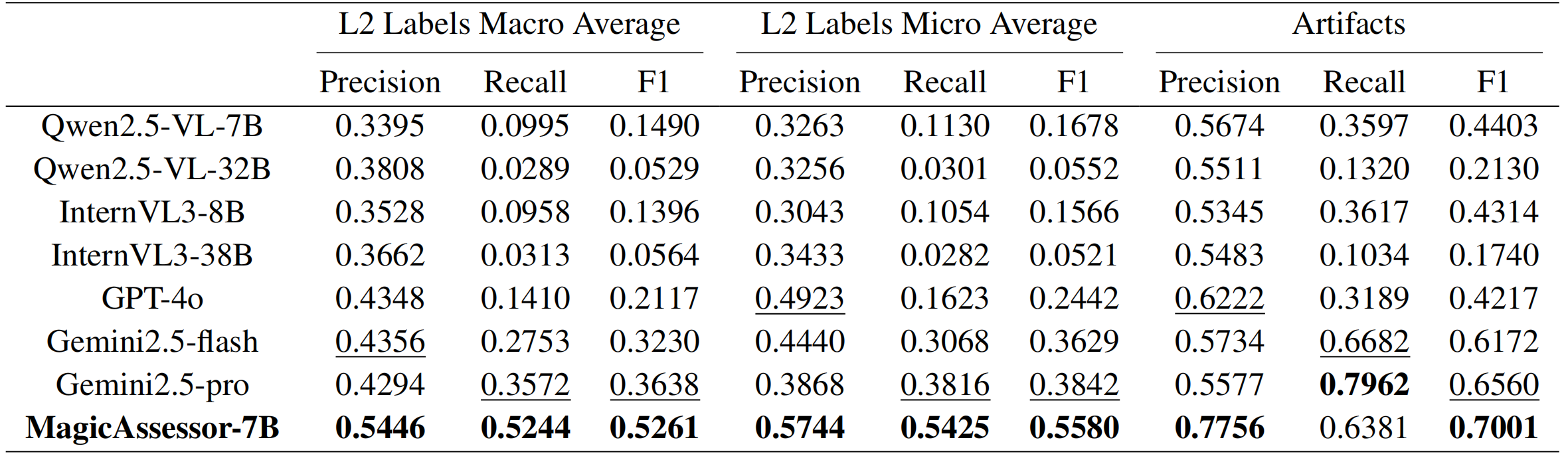
Our model demonstrates strong performance in both detailed artifact detection and overall quality assessment. Compared to existing VLM-based assessors, MagicAssessor achieves the best overall performance, especially excelling in detailed evaluation. It also shows a high correlation with human preferences, outperforming both traditional metrics like CLIP Score and other VLM-based models.
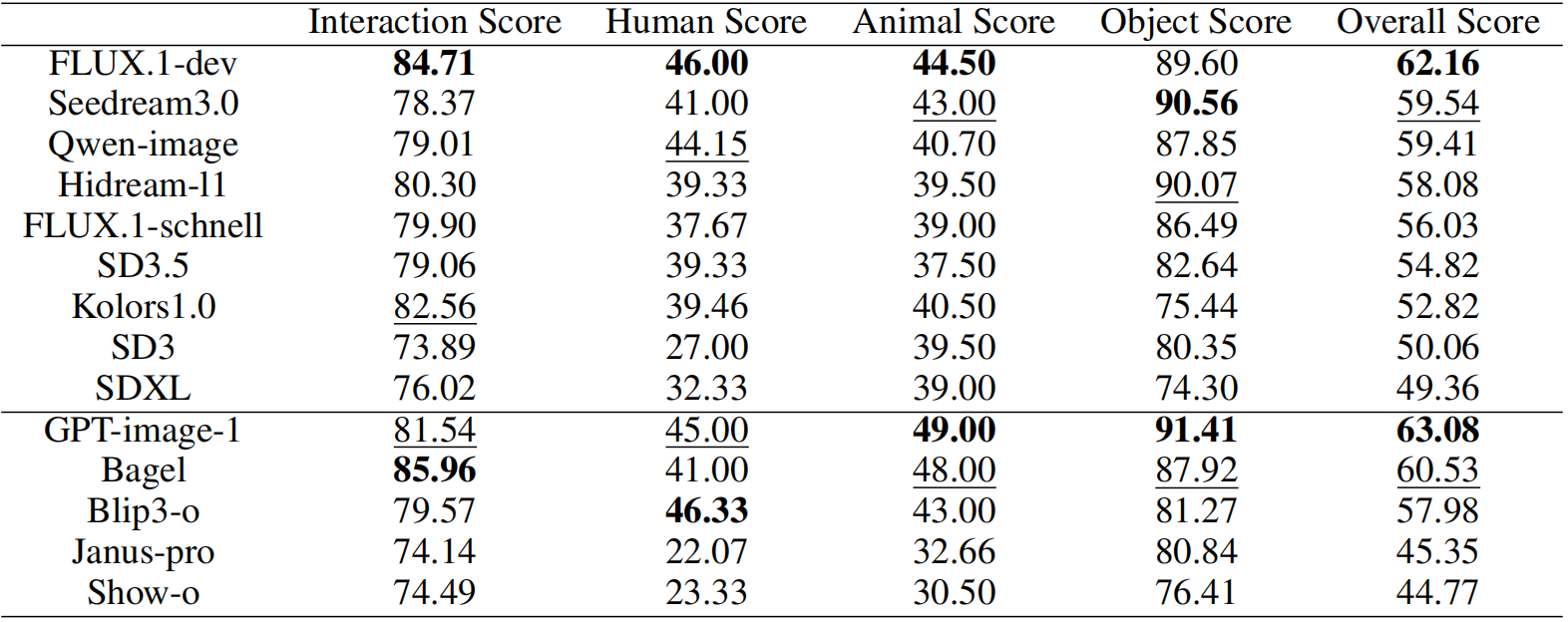
We evaluate various state-of-the-art T2I models using MagicBench. The results show that while some models excel in specific areas, MagicAssessor provides a more balanced and comprehensive assessment. Our benchmark reveals critical insights into the current state of T2I models and highlights the importance of fine-grained artifact evaluation.
@article{wang2025magicmirror,
title = {MagicMirror: A Large-Scale Dataset and Benchmark for Fine-Grained Artifacts Assessment in Text-to-Image Generation},
author = {Wang, Jia and Hu, Jie and Ma, Xiaoqi and Ma, Hanghang and Zeng, Yanbing and Wei, Xiaoming},
journal = {arXiv preprint arXiv:2509.10260},
year = {2025}
}